










EDIfact
Der Begriff steht für Electronic Data Interchange for administration, commerce and transport.
Da dieser Nachrichtenstandard von einer Abteilung der vereinten Nationen, der UNECE (United Nations Economic Commission for Europe) bzw deren Unterabteilung CEFACT gepflegt wird, nennt man diesen Standard auch oft UN/EDIfact. Und da das letzte E in UNECE für Europe steht, wird in Übersee (USA, Australien, …) lieber das prinzipiell ähnliche, aber eben doch wieder andere X12 verwendet.
EDIfact beschreibt ein Datenformat, das heißt den Aufbau von Nachrichten. In der Version D12B werden fast 200 Nachrichtentypen definiert. Version D12B?
Das bedeutet: Verzeichnis der Nachrichtentypen (D für directory), Stand des Jahres 2012, zweite Ausgabe. Üblicherweise gibt es zwei Ausgaben jedes Jahr, in denen neue Nachrichten aufgenommen und bestehende verändert (meist erweitert) werden, und diese beiden Ausgaben heißen A und B. Im Jahre 2001 gab es aber auch noch eine dritte Ausgabe, C. Die Nachrichtenbeschreibungen jeder Version werden allgemein zugänglich gemacht, man kann sie bei der UNECE einfach herunterladen.
Fixed Record
Mit Fixed Record oder Feste Länge ist der Aufbau diverser Datenformate auf unterster Ebene gemeint. Während bei CSV die einzelnen Werte durch Trennzeichen voneinander abgegrenzt werden, sind hier die Längen der Werte entscheidend. Und, wie auch bei CSV, die Reihenfolge. Aus diesen beiden Voraussetzungen folgt, dass jeder Wert im Datensatz eine genau festgelegte Start- und Endposition hat.
Ein einfaches Beispiel
AK 4711 K0815 20130530 POS0001S123 0005000009990 POS0002H456 0003000017950
Dies ist ein extrem simples Beispiel, aber für die Grundlagen reicht’s.
Nehmen wir die Zeilen auseinander.
AK 4711 K0815 20130530
- AK soll hier für den Auftragskopf stehen. Dies ist die Satzartkennung, an der eine Software (oder auch der Mensch) erkennt, um welche Art Datensatz es sich handelt. Sie ist drei Stellen lang, hier aufgefüllt mit einem Leerzeichen.
- 4711 ist die Auftragsnummer, 8 Stellen lang, mit Leerzeichen aufgefüllt.
- K0815 ist die Kundennummer, ebenso lang und aufgefüllt.
- 20130530 schließlich ist das Auftragsdatum, Format yyyymmdd, also 8-stellig.
- Dahinter steht noch ein Leerzeichen, das sehen Sie nur jetzt nicht (aber später).
POS0001S123 0005000009990
- POS ist die Kennung für die Position. Da sie bereits dreistellig ist, muss kein Leerzeichen angefügt werden.
- 0001 ist die Positionsnummer. Sie wird auf eine Länge von 4 Zeichen mit führenden Nullen aufgefüllt.
- S123 ist die Artikelnummer, mit folgenden Leerzeichen auf 8 Zeichen gefüllt.
- 0005 wurde mit Nullen auf Länge 4 aufgefüllt, das ist die Menge.
- 000009990 schließlich soll 9.99 darstellen, vorne mit Nullen aufgefüllt, und statt eines Dezimaltrenners wurde einfach definiert, dass eben immer die letzten drei Ziffern die Nachkommastellen darstellen. Gesamtlänge 9.
Rechnen Sie die Längen dieser Felder mal zusammen! Was kommt raus? Beide Male 28. Um das zu erreichen, wird die Kopfzeile noch mit einem Leerzeichen am Ende aufgefüllt. Gäbe es mehr als diese beiden Satzarten, wären alle so lang, dass die längste Platz hat. Oder man wählt gleich eine übliche „Computer-Zahl“ wie 64, 128 oder 256. Das ist bei solchen Datenformaten ziemlich üblich, aber nicht wirklich zwingend. Im Prinzip kann jede Satzart eine eigene Länge haben, doch die muss dann genau festgelegt sein.
VDA
Das Kürzel steht eigentlich nicht für ein Datenformat, sondern für den Verband der deutschen Automobilindustrie. Dieser wiederum hat für seine Mitglieder sogenannte Empfehlungen herausgegeben, wie sie im EDI-Umfeld ihre Daten untereinander austauschen sollen. Diese Empfehlungen haben Nummern, die letztlich für verschiedene Nachrichtentypen stehen.
Die früheren Empfehlungen beinhalten noch eigene Formate, die wiederum strukturell Fix-Record-Formate sind. Um die wird es in diesem Kapitel gehen. Inzwischen schwenkt der VDA um auf die Benutzung von EDIfact (ein Beispiel ist die VDA-Empfehlung 4938), wodurch sich langsam ein eigenes Subset bildet.
Fortras
Dieser Nachrichtenstandard wird für den Datenaustausch zwischen bzw. mit Speditionen genutzt. Es gibt drei gebräuchliche Nachrichtentypen, das sind Verladeinformationen alias Borderos, Statusberichte und Entladeberichte. Diese wiederum gibt es in mehreren Versionen, genannt „Release“. Release 2 bis 5 (die 1 wurde wohl gleich übersprungen) enthält alle drei Nachrichtentypen, in Release 6 gab es nur kleine Änderungen an den Borderos, und für Release 100 wurden alle drei noch einmal überarbeitet.
Da ein augenfälliger Unterschied zwischen diesen Versionen die Länge der einzelnen Satzarten ist (128 Zeichen bei Release 2-6, 512 Zeichen bei Release 100), kann man die ganze Vielfalt der üblichen Fortras-Nachrichten in folgender, kurzer Liste zusammenfassen:
- Release 2-6 mit 128 Zeichen Satzlänge:
- BORD128: Bordero (Verladeinfos)
- STAT128: Statusdaten
- ENTL128: Entladebericht
- Release 100 mit 512 Zeichen Satzlänge:
- BORD512: Bordero (Verladeinfos)
- STAT512: Statusdaten
- ENTL512: Entladebericht
XML
Die EXtensible Markup Language ist, wie der Name sagt, eine erweiterbare Auszeichnungs-Sprache. Sie ist simpel, gut menschenlesbar und sehr mächtig. Und: Es braucht unglaublich viel Platz. Da allerdings sehr viele Textteile sehr oft wiederholt werden, lässt es sich auch wunderbar komprimieren, was den Nachteil wieder einigermaßen wett macht. Konzentrieren wir uns auf das, was für EDI/EAI wichtig ist.
Der Aufbau
Zuallererst muss gesagt werden, dass die Zeilenumbrüche und Einrückungen in obigem Beispiel der besseren Lesbarkeit dienen. Oft werden Sie Dokumente so formatiert vorfinden, aber im Prinzip kann auch alles in einer Zeile direkt hintereinander stehen. Das ist für die Bedeutung völlig egal. Whitespaces (Zeilenumbruch, Leerzeichen, TAB) außerhalb von Werten haben keinerlei Wirkung. Sollten in bestimmten Werten (beispielsweise Artikelbeschreibungen) Zeilenumbrüche vorkommen, werden die natürlich übernommen. Und nun zu den Bestandteilen.
XML-Header
Eingeleitet wird die XML-Datei vom XML-Header. Der nennt die Version des XML-Formats (eigentlich immer 1.0) und das Encoding, in dem die Datei vorliegt. Außerdem ist hier mit standalone=“yes“ angegeben, dass diese Datei nicht zwingend gegen eine Formatdefinition geprüft werden muss. Mehr dazu etwas später. Dieser Header sollte eigentlich immer existieren, es gibt aber reichlich Beispiele für XML-Dateien, die ohne daherkommen.
Allgemein nennen sich Angaben, die in <? und ?> geklammert sind, „Processing Instructions“. Dieser Header sieht auch so aus, ist aber technisch eigentlich keine. Processing Instructions haben keine direkte Bedeutung für den Daten-Inhalt, daher beschäftigen wir uns nicht näher damit.
Tags und Attribute
Die Bezeichner zwischen < und > nennt man Tags (gesprochen: Täg). Jedes Tag wird, so es nicht ohne Inhalt in der Gegend herumsteht, geöffnet und wieder geschlossen. Man spricht auch vom öffnenden und vom schließenden Tag. Das schließende Tag enthält einfach noch einen Slash / vor dem Bezeichner.
- Auf oberster Ebene, also ohne selbst „Kind“ eines „Vater-Tags“ zu sein, darf es nur exakt einen Tag pro Datei geben: Das sogenannte Root-Tag. Eine XML-Datei, die mehr als ein (öffnendes und sein schließendes) Tag auf oberster Ebene hat, ist ungültig.
- Ein Tag kann einen einfachen Wert beinhalten, wie hier: <AuftragsNr>4711</AuftragsNr>
- Ebenso möglich ist, dass ein Tag weitere Tags beinhaltet, und das beliebig tief geschachtelt. Das obige Beispiel zeigt das sehr schön.
- Ein Tag selbst kann durchaus mehrfach auftreten. So könnte man z.B. die Einordnung eines Artikels in eine Katalogstruktur so darstellen:
<Artikel nr="4711" name="Lernspiel abc">
<Warengruppe>Lernen</Warengruppe>
<Warengruppe>Spiele</Warengruppe>
<Warengruppe>Schule</Warengruppe>
<Warengruppe>Kinder</Warengruppe>
</Artikel>Immerhin passt der Artikel in alle vier Gruppen thematisch gut rein.
Und der Auftrag in unserem Anfangsbeispiel hat ja auch mehrere Positionen.
- Neben Werten und anderen Tags kann so ein Tag auch noch beliebig viele Attribute haben, wie dieses hier: <Position nr=“2″> … </Position>
Der Wert eines Attributs wird – anders als im alten HTML – immer in „“ gesetzt.
Attribute stehen grundsätzlich im öffnenden Tag. Wichtig ist, dass ein Attribut in einem Tag nur einmal auftauchen kann.
So was geht also nicht: <Position nr=“2″ nr=“3″> Wäre auch irgendwie seltsam, welche Nummer hat die Position denn nun? - Und, besonders schön: Ein Tag kann alles auf einmal beinhalten:
- Neben Werten und anderen Tags kann so ein Tag auch noch beliebig viele Attribute haben, wie dieses hier: <Position nr=“2″> … </Position>
<Obertag attr1="bla" attr2="fasel" attr3="dingens">
<Untertag1 noch_n_attr="Vroni">
<UnterUntertag_a>Halli</UnterUntertag_a>
<UnterUntertag_b>Hallo</UnterUntertag_b>
<UnterUntertag_c>Hallöle</UnterUntertag_c>
Das ist der Wert vom Untertag 1.
</Untertag1>
<Untertag2>Ja servus!</Untertag2>
Das ist der Wert vom Obertag.
</Obertag>
- Sollte ein Tag mal weder Wert noch Untertags beinhalten, kann es auch verkürzt geschrieben werden. Man zieht öffnendes und schließendes Tag zusammen:
<Tag_ohne_Inhalt attr1=“Attribute dürfen sein“ />
Sie sehen den Slash / am Ende? Der sagt, das Tag ist hier gleich wieder zu Ende. Es folgt kein schließendes Tag mehr. - Kommentare werden mit <!– eingeleitet und mit –> wieder geschlossen. Sie dürfen über mehrere Zeilen gehen, nur zwischen einzelnen Tags stehen und niemals geschachtelt werden.
BMEcat
Was it BMEcat?
Lassen wir die Homepage des BMEcat-Projektes zu Wort kommen:
Der Bundesverband Materialwirtschaft, Einkauf und Logistik e. V. (BME), Frankfurt a.M., hat eine Initiative zur Entwicklung eines Standards zur elektronischen Datenübertragung für Produktkataloge gestartet, an der sich namhafte Unternehmen mit viel Engagement beteiligt haben. […] Zurzeit liegt der BMEcat in der Version „2005 final draft“ zum Public Review vor. In dieser Phase soll die neue Version durch die Praxis überprüft und eventuelle Fehler gefunden werden. BMEcat 2005 erschließt weitere Branchen und Produktgruppen für den elektronischen Austausch von Produktinformationen. […] BMEcat schafft die Basis für die einfache Übernahme von Katalogdaten aus den unterschiedlichsten Formaten und insbesondere die Voraussetzung, um in Deutschland den Warenverkehr zwischen Unternehmen im Internet voranzubringen. Der XML-basierte Standard BMEcat wurde in vielen Projekten erfolgreich umgesetzt.
Diese Version 2005 ist nach wie vor aktuell und wird auch im openTRANS-Standard mit genutzt. Das heißt, Elemente aus BMEcat 2005 sind auch in den openTRANS-Strukturen zu finden. Sogar die Schemata sind miteinander verknüpft. Oben steht ja schon, dass der Nachrichtenstandard BMEcat XML-basiert ist.
Was kann BMEcat?
Sehen wir uns mal den groben Aufbau der BMEcat-Struktur an:
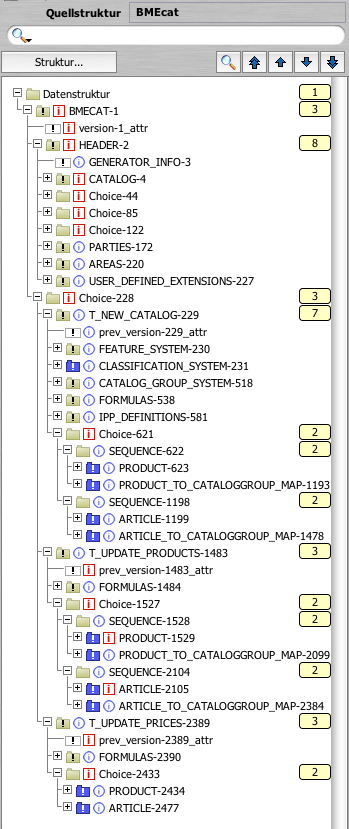 |
| Struktur BMEcat 2005, dargestellt in Lobster_data |
Das Wichtigste zu dieser Struktur zusammengefasst:
- Die Struktur ist ziemlich groß. Alles in allem hat sie über 2500 Elemente (im Baum weitgehend fortlaufend durchnummeriert).
- Es gibt drei Typen von BMEcat-Dateien, die man unterhalb des Knotens Choice-228 sehen kann. Eine Choice (der Ausdruck kommt vom XML-Schema) bietet immer eine Alternative von Elementen, von denen jeweils nur eines vorkommen kann. Also kann hier nur einer der folgenden Inhalte übermittelt werden:
- ein kompletter (neuer) Katalog (T_NEW_CATALOG)
- ein Produktupdate (T_UPDATE_PRODUCTS)
- ein Preisupdate (T_UPDTE_PRICES)
- Will heißen, tatsächlich genutzt wird pro Datei immer nur ein Teil der Gesamtstruktur. Selbst ein kompletter, neuer Katalog besteht insgesamt nur aus etwa 1500 Elementen. Und auch von denen wird immer nur ein kleiner Teil auch wirklich in der Datei erscheinen. Dafür aber bestimmte Elemente sehr oft.
- Ein kompletter Katalog besteht hauptsächlich aus drei großen Teilen:
- die Kataloggruppen
- die Produkte
- die Zuordnung, welche Produkte in welchen Kataloggruppen eingeordnet sind
- Updates beinhalten nur die nötigsten Informationen. Ein Produkt-Update beinhaltet zwar im Prinzip alle Daten zu Artikeln inklusive ihrer Einordnung in Kataloggruppen, aber keinerlei Änderungen an bestehenden Gruppen. Und Preisupdates beschränken sich auf wenige Grundinformationen zu Produkten und eben die Preisangaben. Ändert sich etwas an den Kataloggruppen, ist ein kompletter, neuer Katalog fällig.
- Kataloggruppen können genau einer übergeordneten Gruppe im Sinne einer Baumstruktur zugeordnet werden. Produkte dagegen können vielen unterschiedlichen Kataloggruppen angehören.
- Unabhängig von obigen drei Typen gibt es gewisse allgemeine Informationen im Header, wie z.B. den betroffenen Katalog, die Sprache, beteiligte Parteien usw.
- Reichen einem die im Standard verfügbaren Elemente nicht aus, können sogenannte „User defined extensions“ vereinbart werden. Dies ermöglicht bedarfsgerechte Erweiterungen des Formats. Dazu müssen sich aber alle beteiligten Parteien abstimmen!
Wer benutzt BMEcat und was kostet es?
Eigentlich jeder, der Katalogdaten austauschen will. Allen voran sicher das produzierende Gewerbe und der Handel. Laut Selbstdarstellung des BME ist das Format inzwischen der „de facto Standard für den Austausch elektronischer Produktkataloge“ und vor allem im deutschsprachigen Raum verbreitet, aber man will natürlich expandieren.
Die Nutzung des Formats ist kostenlos. Nach (ebenfalls kostenfreier) Registrierung auf der Homepage erhält man Zutritt in den Download-Bereich, wo einem dies mitgeteilt wird. Außerdem stehen dort Formatbeschreibungen zu den verschiedenen Versionen in unterschiedlichen Dateiformaten zur Verfügung, unter anderem PDF und XSD.
openTrans
Was ist openTRANS?
Ein Zitat der openTRANS-Homepage gibt Aufschluss:
Die openTRANS-Initiative mit führenden deutschen und internationalen Unternehmen unter der Leitung von Fraunhofer IAO, hat sich die Standardisierung von Geschäftsdokumenten (Auftrag, Lieferschein, Rechnung etc.) zum Ziel gesetzt, die Grundlage für die elektronische System-zu-System-Kommunikation ist. Im Rahmen eines Expertenkreises werden die Geschäftsdokumente auf XML-Basis definiert und Integrationslösungen für Einkäufer, Lieferanten und Marktplatzbetreiber erarbeitet.
Man kann also openTRANS als Nachrichtenstandard bezeichnen, der als zugrunde liegendes Datenformat XML nutzt. Die Wahl von XML ist eine gute Idee, denn damit kann jede Software, die XML beherrscht, auch openTRANS-Dokumente lesen bzw. erzeugen.
Übrigens sind openTRANS und BMEcat eng miteinander „verbandelt“, die Schemata zu openTRANS nutzen sogar Typen und Elemente aus der BMEcat-Welt.
Und was gibt es da nun für Dokumente? Stand September 2013 ist openTRANS Version 2.1 aktuell, und die enthält:
- RFQ (Request For Quotation, Angebotsanforderung)
- QUOTATION (Angebot)
- ORDER (Auftrag bzw. Bestellung)
- ORDERCHANGE (Auftragsänderung)
- ORDERRESPONSE (Auftragsbestätigung)
- DISPATCHNOTIFICATION (Lieferavis)
- RECEIPTACKNOWLEDGEMENT (Wareneingangsbestätigung)
- INVOICE (Rechnung)
- INVOICELIST (Rechnungsliste)
- REMITTANCEADVICE (Zahlungsavis)
(Diese Liste stammt von der openTRANS-Homepage.)
Können und dürfen Sie openTRANS benutzen?
Zuerst einmal zum Dürfen: Ja. Und das sogar kostenlos.
Da unsere Aussage natürlich nicht das Maß der Dinge ist: Die genaueren Nutzungsbedingungen finden Sie in den FAQs der openTRANS-Homepage.
Jetzt zum Können: Durch die Wahl von XML als grundlegendes Datenformat dieses Nachrichtenstandards sollte jede EDI/EAI-Software, die XML generell beherrscht, auch mit openTRANS-Dokumenten klarkommen. Nach kostenfreier Registrierung auf der Homepage können Sie dort Formatbeschreibungen sowohl in menschenlesbarer Form (PDF) als auch maschinenlesbar als XML-Schemata herunterladen. Der Rest ist, je nach Software, Fleißarbeit.
CSV
Das Kürzel steht für Comma Separated Values, also kommagetrennte Werte. Allerdings wird das mit dem Komma nicht so eng gesehen. Im Prinzip kann jedes Zeichen als Trennzeichen verwendet werden, sinnvoll sind natürlich möglichst die Zeichen, die in den Werten selbst eher selten vorkommen. Sehr beliebt ist neben dem Komma noch das Semikolon (Strichpunkt ; ), aber in freier Wildbahn trifft man auch auf die Pipe (senkrechter Strich | ), das AT-Zeichen (Klammeraffe @), den Tabulator und so ausgefallene Ideen wie nicht-druckbare Zeichen (zum Beispiel ASCII 7 = Bell, also ein Piepser).
Ein einfaches Beispiel
AK;4711;K0815;30.05.2013
POS;1;S123;5;9.99
POS;2;H456;3;17.95
Hier wird das Semicolon als Trennzeichen verwendet. Sie sehen, CSV ist ein unglaublich sparsames Format, da zu jedem Wert nur noch ein einzelnes Zeichen als Trenner kommt. Und am Ende eines Datensatzes steht üblicherweise ein Zeilenumbruch, auch das ein Zeichen oder schlimmstenfalls zwei. Da kann Fix Record oder gar XML bei weitem nicht mithalten.
Nehmen wir die Zeilen auseinander.
AK;4711;K0815;30.05.2013
- AK soll hier für den Auftragskopf stehen. Dies ist die Satzartkennung, an der eine Software (oder auch der Mensch) erkennt, was für ein Datensatz folgt.
- 4711 ist die Auftragsnummer
- K0815 ist die Kundennummer
- 30.05.2013 schließlich ist das Auftragsdatum, übliches deutsches Format dd.mm.yyyy
POS;1;S123;5;9.99
- POS ist die Kennung für die Position.
- 1 ist die Positionsnummer.
- S123 ist die Artikelnummer.
- 5 ist die Menge.
- 9.99 zu guter Letzt ist der Einzelpreis
Anders als bei Fix Record empfiehlt es sich bei CSV nicht, auf Zeilenumbrüche zu verzichten. Denn es gibt hier eine sehr praktische Regelung: Folgen in einem Datensatz keine Werte mehr, kann man auch die Trennzeichen weglassen. Angenommen, nach dem Einzelpreis könnte in einer Positionszeile noch der Name und die Beschreibung des Artikels folgen:
POS;1;S123;5;9.99;USB-Stick;Speicherstick mit USB 3.0 und 4 GB Kapazität
Dann müsste man, wenn man diese beiden Texte weglassen will, nicht etwa so schreiben:
POS;1;S123;5;9.99;;
Sondern man kann die letzten beiden ; einfach weglassen. In einer Fix Record-Datei müsste man die Zeile noch extra mit Leerzeichen aufblähen und könnte dafür gerade mal auf den Zeilenumbruch verzichten.
IDoc
Ein Format, in dem SAP-Systeme ihre Daten ausgeben bzw. einlesen können.
Auf unterer Ebene ist IDoc eine FixRecord-Struktur. Oder auch XML, je nach dem.
Da aber das Format selbst schon verwirrend genug ist, klären wir den vorigen Satz gleich mal auf. SAP bietet für den Austausch kompletter Dokumente schon seit langem die sogenannte ALE-Schnittstelle an. Dazu schauen Sie bitte in das oben genannte Kapitel. Via ALE werden IDocs im FixRecord-Format ausgetauscht. Die ALE-Kommunikation war ursprünglich nur für den Austausch zwischen zwei SAP-Systemen gedacht. Seit einiger Zeit bietet SAP aber zur Kommunikation mit der Außenwelt (also nicht-SAP-Software) das Modul PI (bzw. vormals XI) an. Und das wiederum „spricht“ XML. Die XML-Strukturen sind im großen und ganzen Umsetzungen der alten FixRecord-Strukturen, nur eben in XML-Tags gehüllt. Das heißt, der Inhalt ist (bis auf ein paar Kopffelder, die in XML wegfallen, und die eine oder andere Winzigkeit) derselbe, ob FixRecord- oder XML-IDoc.
Aufbau
Der Aufbau von IDocs ist komplex. Schauen wir uns einmal einen Strukturbaum zu einem ORDERS05, also einem Auftrag, an:
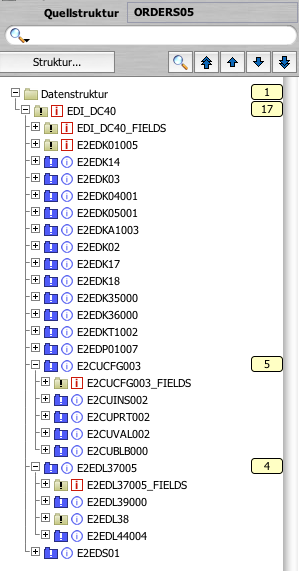 | 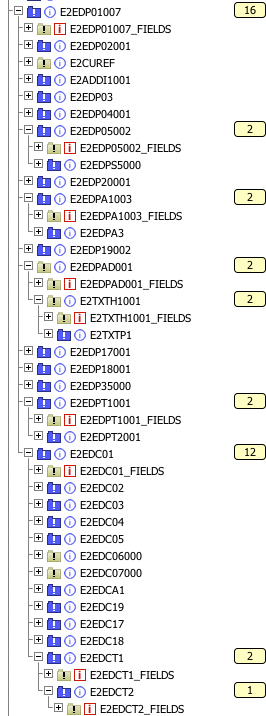 |
| Struktur des IDocs ORDERS05, dargestellt in Lobster_data | Struktur des Knotens EDP01 |
Links sehen Sie den groben Aufbau des IDocs, rechts ist der Knoten E2EDP01007 einzeln, aufgeklappt dargestellt (links steht er ziemlich mittig, eine Zeile über der gelben 5). Das P steht für die Position, der Knoten und alle seine Unterknoten enthalten Daten zu je einer Position.
Wir sprechen von Knoten, aber das ist natürlich nur die Darstellung in dieser speziellen Software. Im IDoc finden Sie ganz einfach Segmente, also eine Satzartkennung vorweg und dann viele Daten.
Das im Detail zu erläutern, ersparen wir Ihnen lieber. Nur ein paar Punkte:
- Jedes IDoc beginnt grundsätzlich mit einem Satz der Satzart EDI_DC40. An dem EDI in dieser Kennung sehen Sie, dass sie für den elektronischen Datenaustausch gedacht sind. So ein EDI_DC40 sieht auch im Aufbau immer gleich aus, egal, welche Art von IDoc man vor sich hat (über Versionen hinweg kann sich dann schon etwas ändern…). Hier stehen so grundlegende Informationen wie:
- Typ und Version des IDocs (z.B. eben ORDERS05)
- Mandant des SAP-Systems, dem es gehört
- Dokumentennummer
- Message-Typ (dazu später mehr)
- Sender und Empfänger-Informationen
- Datum/Zeitstempel
- usw.
- Ein IDoc-Typ (wie ORDERS) kann mehrere Message-Typen beinhalten. Z.B. kann nicht nur ein Auftrag, sondern auch die Auftragsbestätigung in einem IDoc der Art ORDERS enthalten sein. Das steht dann im Feld für den Message-Typ.
- Jeder Segment-Typ wird innerhalb SAP durch einen Struktur-Datentyp dargestellt, der die Anzahl, Größen, Typen und Namen der Felder in ihrer Reihenfolge definiert. Diese Strukturtypen haben alle einen Namen, der mit E1 beginnt, z.B. E1EDP01. In der Satzartkennung eines Fixrecord-IDocs beginnt der Name der Satzart aber mit E2, also E2EDP01. Wegen der Satzartkennungen heißen die Knoten in obigen Bäumen auch so (mit E2 am Anfang). Bei XML-IDocs heißen die Tags allerdings wieder E1…, weil sie einen Typnamen darstellen.
- Sowohl die IDoc-Typen (wie ORDERS) als auch die einzelnen Satzarten (wie EDP01) haben eigene Versionen. ORDERS05 ist also Version 5 des ORDERS-IDoc, und EDP01007 ist Version 7 der Satzart EDP01. Wie Sie sehen, fehlt aber zum Beispiel beim EDK14 (erster blauer Knoten im linken Bild) eine Versionsnummer. Hier wird die Grundform genutzt, keine veränderte Version.
- Für FixRecord-IDocs gilt: Jedes Segment beginnt mit einem halben Dutzend Felder, in denen zum Beispiel Mandant und Dokumentennummer stehen. Alle Segmente eines IDocs müssen hier dieselben Werte haben. Außerdem werden Vater/Kind-Beziehungen zwischen Segmenten hergestellt. Aufgrund des hierarchischen Aufbaus der XML-IDocs sind diese Felder dort nicht nötig.
- Bei XML-IDocs ist der Name des Root-Elements identisch zum Message-Typ, es folgen ein oder mehrere Elemente IDoc und darin dann jeweils das eigentliche IDoc, beginnend mit Steuersatz EDI_DC40.
- SAP-Systeme sind oft stark auf die Bedürfnisse des jeweiligen Betreibers zugeschnitten. Auch die Dokumentenarten weichen dann vom Standard, den ein jungfräuliches SAP bietet, ab. Das Ganze nennt sich dann CIM-Typen. Will heißen, dass auch IDocs desselben Typs und der selben Version von SAP-Installation zu SAP-Installation unterschiedlich aussehen können.
Das gesamte IDoc-Format ist mehr oder weniger ein Tabellen-Dump im FixRecord-Format. Da es ursprünglich nur zur direkten Kommunikation zwischen zwei SAP-Systemen gedacht war und nicht, um Dateien in diesem Format durch die Welt (und in Fremdsoftware) zu schicken, ist das auch ganz in Ordnung.
Die XML-Dateien, die ein SAP XI oder PI ausgibt, sind im Standard, abgesehen von der XML-Verpackung, sehr ähnlich aufgebaut wie die FixRecord-IDocs. Satzarten und Felder stimmen praktisch überein, abgesehen von den genannten Kopffeldern. Hier kann natürlich am Ausgabeformat gedreht, also von den Standard-IDocs abgewichen werden. Erfreulich ist aber die Tatsache, dass jedes SAP-System fähig ist, die Formatbeschreibung seiner IDocs auszugeben. Für Fix Record IDocs sind das die sogenannten IDoc Parser Files, für XML-IDocs bekommen Sie ein XML Schema. Beides erhalten Sie in der Transaktion WE60.
Wenn Sie sich tatsächlich in die Tiefen der IDocs stürzen wollen, empfehlen wir folgenden Link:
Aufbau, Dokumentation und Definition von IDoc-Typen
Was für Sie wichtig ist
Wenn Sie entweder selbst ein SAP-System besitzen oder Ihre Partner ankündigen, Ihnen IDocs zu schicken bzw. welche von Ihnen haben wollen, sollten Sie auf eine umfassende Integration dieses Dokumententyps bzw. der SAP-Kommunikation achten. Idealerweise kann die Software direkt mit SAP sprechen und die auf genau dieser Installation gültigen Strukturen selbst erfragen (Stichwort CIM-Typen). SAP bietet, wie schon gesagt, auch die Möglichkeit, Beschreibungen seiner Strukturen zu exportieren. Diese sollten entsprechend eingelesen werden können, damit Ihnen auch Ihre Partner direkt die passenden Strukturen zu ihren IDocs geben können.
ANSI ASC X12
steht für American National Standards Institute Accredited Standards Committee X12. Dieser Nachrichtenstandard definiert über 300 Nachrichtentypen aus allen möglichen Bereichen wie Handel, Transport und Versicherungen. Auch sonst gibt es viele Parallelen zu EDIfact, was nicht von ungefähr kommt, da X12 ein Vorläufer von EDIfact ist. Allerdings ist dieser Vorläufer immer noch in Gebrauch, gerade in den USA, aber zum Beispiel auch in Australien. Das X12-Komitee selbst führt X12 als Nationalen Standard und verweist zu internationalen Standards auf eine Seite der UN/CEFACT, die unter anderem dann auch wieder auf UN/EDIFACT verweist. Man möchte also eigentlich meinen, wir hier in Europa müssten uns mit diesem X12-Kram gar nicht herumschlagen, denn immerhin wird ja EDIfact als internationaler Standard anerkannt. So einfach ist es aber leider nicht. Wer mit Geschäftspartnern in Übersee zu tun hat, hat in der Regel auch mit X12 zu tun. Daher hier also ein paar nähere Informationen dazu:
Beispiel
Hier eine kleine X12-Datei mit einem Auftrag:
ISA* * * * *ZZ*SENDER *ZZ*RECEIVER *041201*1200*U*00305*000000101*1*P*^
GS*PO*SENDER*RECEIVER*041201*1200*101*X*003050
ST*850*000000101
BEG*22*NE*101**041201*123456
FOB*DF*ZZ*JMJ
DTM*037*041205
DTM*038*041215
DTM*002*041218
TD1*CNT90*1
TD5****JJ*X
TD3*40
N1*OB**92*7759
N3*111 Buyer St
N4*Conyers*GA*30094*US
N1*SE*Foo Bar Sellers
N4****US
REF*DP*101
PO1*100*1*EA***ZZ*BL47*HD*100
PID*F****Widget
PO4**1*EA
N1*CT**38*CN
N4****CN
CTT*1*100
SE*22*000000101
GE*1*101
IEA*1*000000101
Wenn Sie den Artikel zu EDIfact noch nicht gelesen haben holen Sie das am besten jetzt nach (siehe Reiter oben). Denn die Logik der Segment-Abfolge ist eine ganz ähnliche. Zur Verdeutlichung hier ein Teil der Struktur zum Nachrichtentyp 850 (Purchase Order):
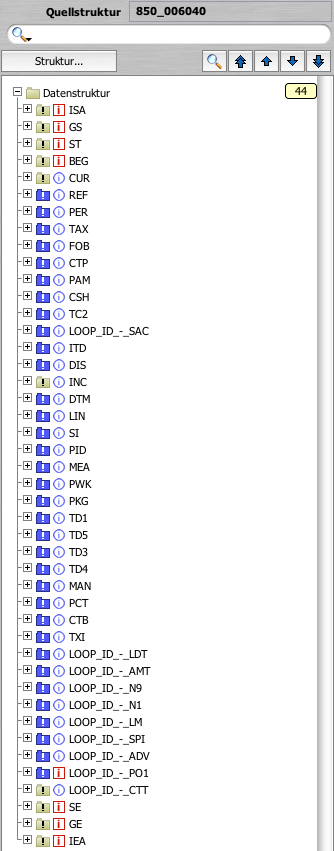 | 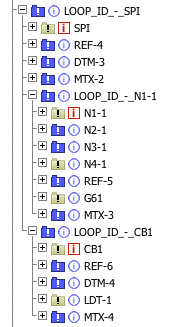 |
| X12 Nachricht 850 – Puchase Order (Version 006040), dargestellt in Lobster_data | Der Loop SPI der X12 Nachricht 850 |
Was in EDIfact die Segmentgruppen (SG1 bis SGx) sind, nennt sich bei X12 „Loops“, die Logik ist dieselbe. Einzelne Segmente können sich wiederholen. Soll eine Gruppe wiederholt werden, zeigt immer das erste Segment der Gruppe (bzw. des Loops) an, dass es wieder von vorn los geht. Auch hier gilt: Sind wir in der Struktur einmal an einer bestimmten Stelle vorbei, können wir nie wieder zurück.
Die Details
Unterschiede
In den Details unterscheidet sich X12 doch ein wenig von EDIfact:
- Zum einen gibt es nichts, das dem UNA-Segment entspräche. Stattdessen werden die benutzten Trennzeichen anhand ihrer Position im ISA-Segment erkannt:
- Das Zeichen direkt nach „ISA“ ist der Feldtrenner (im Beispiel ein *)
- An Stelle 105 findet man das Trennzeichen für Werte innerhalb von Components alias Composites (hier das ^)
- Das Zeichen, danach ist der Segmenttrenner. In unserem Fall ist also der Zeilenumbruch der Segmenttrenner.
- Der Dezimaltrenner wird nicht vorgegeben, und auch ein Escape-Character fehlt.
Das gesamte ISA-Segment ist wie ein Fix Record Datensatz aufgebaut.
- Etwas, das es bei EDIfact zwar neuerdings gibt, dort aber nicht genutzt wird, ist der sogenannte „Repetition Character“. Der findet sich an Position 83. Im obigen Beispiel steht da ein U, und das bedeutet „Unused“, also ungenutzt. Wird er genutzt, kann sich ein Feld oder eine ganze Composite innerhalb eines Segments mehrfach wiederholen, wobei die einzelnen Wiederholungen eben durch dieses Zeichen getrennt sind. Allerdings muss das schon in der Nachrichtenbeschreibung so vorgegeben sein, und das ist nicht allzu häufig der Fall.
- Subsets zu X12 gibt es nicht. Das X12-Komitee verlangt für die Formatbeschreibungen jeder neuen Version Geld.
- Die Nachrichtentypen werden über ihre Nummer (im Beispiel 850) identifiziert. Das sprechendere „PO“ (für Purchase Order) im GS-Segment ist nicht unbedingt damit gleichzusetzen, denn dieses bezeichnet eine funktionale Gruppe, also u.U. mehrere Nachrichtentypen, die thematisch zusammengehören. Die funktionale Gruppe „SO“ enthält z.B. zehn verschiedene Nachrichtentypen (Version 006040).
- Segment-Kennungen müssen nicht, wie bei EDIfact, drei Zeichen lang sein. Zwei reichen manchmal auch.
Gemeinsamkeiten
- Wie gerade gelesen, gibt es also auch bei X12 Segmente, normale Felder und Composites (auch Components genannt). Und die Loops entsprechen den Segmentgruppen.
- Auch X12 kennt diverse Steuersegmente, die Dateien einleiten bzw. Nachrichten klammern:
- ISA entspricht in etwa einer Kombination aus UNA und UNB. Auch hier stehen unter anderem beteiligte Parteien, Datum/Uhrzeit und eben die wichtigsten Sonderzeichen. Eine Zeichensatz-Vorgabe gibt es nicht, dieser ist in X12 auf ASCII festgelegt.
- GS und GE klammern analog zu UNG und UNE eine Gruppe thematisch zusammengehöriger Nachrichten (funktionale Gruppe). Im Beispiel oben steht im GS-Segment „PO“ für „Purchase Order“
- ST und SE wiederum klammern eine Nachricht, wie das bei EDIfact UNH und UNT tun. Im obigen ST steht der Code 850 für den Nachrichtentyp, eben eine Purchase Order.
- Am Ende schließt der IEA-Satz die Datei ab, wie ein UNZ bei EDIfact. Da Gruppen bei X12 Pflicht sind, steht hier die Anzahl der enthaltenen Gruppen (GS/GE).
- Auch in den Pärchen ISA/IEA, GE/GE und ST/SE finden sich Identifikationsnummern, die die Zusammengehörigkeit sicherstellen. Und auch SE enthält einen Zähler aller Segmente dieser Nachricht, einschließlich SE. Entsprechend enthält auch GE die Anzahl Nachrichten (alias Transaction Sets) innerhalb seiner Gruppe.
Natürlich gibt es auch bei X12 eine Weiterentwicklung. Die Versionen werden hier anders benannt. So bedeutet z.B. die Versionsnummer 006040:
Version 6, Ausgabe (release) 4, Unterausgabe (subrelease) 0.
Übrigens steht am Ende des GS-Segments (und auch im ISA-Segment) unserer Beispielnachricht, dass diese zur X12-Version 003050 gehört. Also schon ein bisschen veraltet…
ENGDAT
ENGDAT ist weder ein Datenformat noch ein Nachrichtenstandard im engeren Sinne. Was
ENGDAT steht für Engineering Data Message und ist ein definierter Workflow zum Austausch von technischen Dokumenten, vornehmlich in der Automobilbranche. Neben dem Austausch von technischen Dokumenten können auch Kontaktinformationen ausgetauscht werden – hierbei handelt es sich um sogenannte ENGPART-Mitteilungen, die in einer ENGDAT-Nachricht übermittelt werden.
Die aktuelle Spezifikation von ENGDAT ist V3.1, die aktuelle Version von ENGPART ist V4.1.
Tiefergehende Informationen über ENGDAT finden Sie beim Verband der Automobilindustrie VDA und bei der Strategic Automotive product data Standards Industry Group, kurz SASIG.
Zur Datenübertragung hat sich das OFTP-Protokoll als Standard durchgesetzt.
Gerade in der Automobil-Branche (also alles rund um’s Auto, Zubehör, Ersatzteile, Transport usw.) werden jede Menge CAD-Dateien ausgetauscht. CAD steht für Computer-Aided Design, also für die Konstruktion von Produkten, Bauteilen u.ä. am Computer.
Nun sind in solchen CAD-Dateien nun mal rein technische Informationen enthalten, nicht aber Organisatorisches, wie Ansprechpartner, involvierte Abteilungen usw. Solche Daten – man nennt sie auch Metadaten – müssen zusätzlich zu den reinen CAD-Dateien übertragen werden, wobei sichergestellt werden soll, dass auch die richtigen CAD- und Zusatzdateien zusammen bleiben. Die Metadaten, die zusammen mit den Nutzdaten zur ENGDAT-Nachricht gehören, enthalten z.B. Informationen über Sender und Empfänger oder auch den Zweck der Daten.
Allgemeine Kontaktinformationen, die Partnerstammdaten, werden über ENGPART-Nachrichten ausgetauscht.
Außerdem gehört zur Zusammenarbeit in diesem Bereich auch, dass man beim Partner (Lieferanten/Kunden) bestimmte Dokumente anfragt oder umgekehrt bestätigt, dass man sie erhalten hat. Solche definierten Abläufe nennt man Workflow.
Dass zur Übertragung der Daten OFTP benutzt wird, ist nicht offiziell vorgegeben. Allerdings kommt das OFTP-Protokoll, genau wie ENGDAT, aus der Automotive-Branche und hat sich dort als Standard-Übertragungsweg etabliert. Bis vor relativ kurzer Zeit wurde noch das OFTP über ISDN-Leitungen genutzt, inzwischen stellen die ersten Unternehmen auf das TCP/IP- und TLS-basierte OFTP2 um.
Die technische Seite
Die Übertragung per OFTP wurde unter Kommunikationswege erläutert.
Aber wie wird zum Beispiel kenntlich gemacht, welche Dateien einer Übertragung zusammengehören? Immerhin könnten ja auch in einer einzigen Verbindung mehrere ENGDAT-Nachrichten daherkommen.
Diese Problem wird durch das Dateimuster gelöst:
Jede Datei bekommt bei der Übertragung einen logischen Dateinamen. Und der ist großenteils für alle Dateien einer Nachricht identisch, bis auf einen fortlaufenden Zähler.
Konkret sieht das so aus, unterschieden nach ENGDAT Version 2 und 3:
- ENGDAT V2: „ENG“ oder „EN2“ + Zeitstempel im Format „yyMMddHHmmss“ + Route (alias Adresscode, fünf Zeichen) + Anzahl der technischen Dokumente (drei Zeichen) + Zähler der aktuellen Datei (drei Zeichen)
Ein Beispiel für die erste von vier Dateien am 21.02.2013 12:30 mittags wäre also: ENG130221123000ROUTE004002. Alles in allem 26 Zeichen. - ENGDAT V3: „ENG“ oder „EN3“ + Zeitstempel im Format „yDDDHHmmss“ + Route (alias Adresscode, fünf Zeichen) + Anzahl der technischen Dokumente (vier Zeichen) + Zähler der aktuellen Datei (vier Zeichen)
Dieselbe Datei in V3 hieße also: ENG3052123000ROUTE00040002. Auch hier haben wir 26 Zeichen.
Das Datumsformat ist recht seltsam. Es wird nur die letzte Ziffer der Jahreszahl (3 von 2013) genutzt und der Tag im Jahr komplett durchgezählt, also von 001 bis 365 (bzw. 366).
In den beiden Beispielen würden also jeweils 4 zusammengehörige Dateien versendet, deren logischer Dateiname sich nur im fortlaufenden Zähler ganz hinten unterscheidet. Da auch die Gesamtzahl der Dateien mit drin steht, merkt man gleich, wenn eine Datei fehlt, und kann diese nachfordern.
Als nächstes müssen wir über die Datenformate sprechen.
Die CAD-Daten selbst (die Nutzdaten) befinden sich in einem der CAD-Formate, die so von den verschiedenen Programmen genutzt werden. Natürlich müssen sich die beteiligten Parteien auf ein Format einigen.
Aber wie sehen Metadaten und ENGPART-Nachrichten aus?
Früher wurde für diese Daten EDIfact genutzt, in den aktuellen Versionen (ENGDAT V3 und ENGPART V4) kommt XML zum Einsatz. Näher brauchen wir nicht darauf einzugehen, damit dürfen Sie sich herumschlagen, wenn Sie tatsächlich auch ENGDAT nutzen wollen. Wobei diese „low level“-Dinge eigentlich von der genutzten Software erledigt werden sollten, ohne dass Sie sich direkt damit beschäftigen.
Kommen wir zu den definierten Nachrichtentypen. Generell wird eine V3-Engdat-Nachricht in „Conformance Classes“ (CC) unterschieden:
- CC1: Anfrage von Dokumenten (wird im Aufbau nochmals in a und b unterschieden)
- CC2: Senden von Dokumenten ohne zusätzliche Informationen über enthaltene Dateien
- CC3: Senden von Dokumenten mit zusätzlichen Informationen über enthaltene Dateien
- CC4: Bestätigung einer eingehenden Nachricht (wird im Aufbau nochmals in a und b unterschieden)
- CC5: gibt es nicht als Nachricht; man spricht von einer Conformance Class 5, wenn die eingesetzte Software CC1 bis CC4 unterstützt.
Bleibt noch zu sagen:
Eigentlich sollten ja bei EDI die Daten vollautomatisch zwischen den IT-Systemen der beteiligten Partner ausgetauscht werden. Ohne Eingriff des Menschen. Im Falle ENGDAT ist diese reine Lehre nicht durchzuhalten. Hier muss der Versand interaktiv von einem Mitarbeiter erledigt werden, der die zu den Nutzdaten gehörigen Metadaten bestimmt bzw. eingibt und sich auch um die Pflege der Partnerstammdaten kümmert. Zwar läuft der Austausch der Daten weitgehend automatisch, doch ein wenig Handarbeit muss einfach sein. Wenn Sie also bereits ENGDAT betreiben oder die Wahrscheinlichkeit besteht, dass dieses Thema in Zukunft ansteht, dann achten Sie bei der Auswahl ihrer EDI-Software darauf, dass sie auch eine vernünftige ENGDAT-Integration bietet.
BWA
Das Format stammt aus dem deutschen Buchhandel. Es ist ein Nachrichtenstandard, der insgesamt vier verschiedene Nachrichten umfasst:
- Bestellsatz
- Lieferscheinsatz
- Rückmeldung
- Titelstammsatz
Das zugrundeliegende Format ist eine etwas abenteuerliche Mischung aus CSV und FixRecord.
Zum Glück gilt dieses Format inzwischen als veraltet. Der Börsenverein des deutschen Buchhandels empfiehlt seit einiger Zeit, doch lieber auf das EDIfact-Subset zu setzen, da dieses mehr Möglichkeiten bietet.
Trotzdem hier zur Veranschaulichung der Aufbau eines Bestellsatzes im BWA-Format:
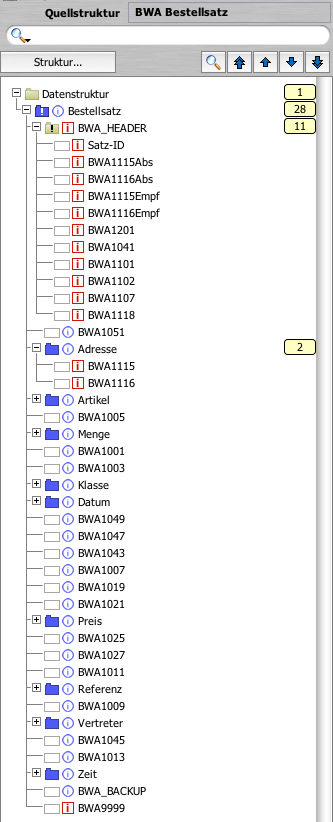 |
| BWA Bestellsatz, dargestellt in Lobster_data |
MS Excel
Eines vorweg: Excel ist kein Datenaustauschformat im Sinne von EDI!
Leider wird es aber immer noch von einigen als solches verwendet!
Excel bedeutet meist manuell ausgefüllte Formulare, die immer wieder kleine oder auch größere Abweichungen aufweisen und für die vollautomatische Bearbeitung denkbar ungeeignet sind. Besonders phantasievolle Zeitgenossen versenden auch Excel-Dateien, die intern Verweise auf andere Excel-Dateien enthalten – und im schlechtesten Fall nicht einmal mitgeschickt wurden.
Unser Rat: Vermeiden Sie den Datenaustausch im Excel-Format! Excel kann Daten nach CSV exportieren bzw. dieses auch wieder importieren. Das ist immer noch besser als direkt via Excel zu kommunizieren. Wir sprechen hier schließlich von automatischen Prozessen und nicht davon, dass sich ein Sachbearbeiter eine Excel-Datei am Bildschirm anschaut und die Inhalte per Hand in sein System überträgt.
Sollte es sich gar nicht vermeiden lassen, nun gut. Moderne Konverter können auch Excel ausgeben bzw. einlesen. Aber Sie (und Ihr Partner) müssen damit leben, dass man sich nicht auf reibungslose, vollautomatische Verarbeitung verlassen kann, wie sie eigentlich bei EDI gefordert und bei Nutzung von Standard-Formaten auch möglich ist.
Für PDF gilt ähnliches wie für Excel: Es ist für Menschen da, die es sich am Bildschirm ansehen oder ausdrucken. Es ist nicht für die Verwendung in EDI-Prozessen gedacht und auch nicht dafür geeignet.
Nur in seltenen Fällen, wenn PDF-Dateien vollautomatisch und immer verlässlich mit demselben Aufbau erzeugt wurden, kann man sie in begrenztem Umfang automatisch weiterverarbeiten. Ist dies nicht gegeben, hilft eigentlich nur noch eine OCR-artige Vorbehandlung, die das, was der Mensch sieht, wieder in einigermaßen maschinenlesbare Form bringt.
PDF ist eine tolle Erfindung und wird ja auch (oft im Zusammenspiel mit elektronischer Signatur) eingesetzt, um Rechnungen und ähnliches manipulationssicher zu archivieren. Aber für EDI ist es schlicht ungeeignet.


